0x00 前言
之前做题的时候碰到了CRLF,但是毫不客气的说。我没有搞懂!没办法,准备放一放的,没想到一放就放到了现在。恰巧峰佬突然更了一篇博客让我想起了这件事。这里刚好结合峰佬的博客来看一看让我头疼的CRLF。
0x01 CRLF介绍
CRLF的别名是HTTP走私攻击。 是一种干扰网站处理从一个或多个用户接收的HTTP请求序列的方式的技术。 它使攻击者可以绕过安全控制,未经授权访问敏感数据并直接危害其他应用程序用户。
当今的Web应用程序经常在用户和最终的应用程序逻辑之间使用HTTP服务器链。 用户把请求发送给前端服务器,并且前端服务器把请求转发到一个或多个后端服务器。
当前端服务器将HTTP请求转发到后端服务器时,他会通过统一后端网络发送多个请求(一个连接,多个请求)。因为这样做效率更高且性能更高。该协议非常简单:HTTP请求一个接一个地发送,接受服务器解析HTTP请求标头以确定一个请求在哪里结束,下一个请求在哪里开始。
前端和后端系统就请求之间的边界达成一致。否则,攻击者可能会发送一个模棱两可的请求,该请求被前端和后端系统以不同的方式解释(攻击者使得前端请求的一部分被后端解释执行为下个请求的开始,干扰后端应用程序处理该请求的方式)。
0x02 CRLF原理
大多数HTTP请求走私漏洞的出现是因为HTTP规范提供了两种不同的方法来指定请求的结束位置:Content-Length头和Transfer-Encoding头。产生的方式就是同时采用两种方式,前后端服务器分别采用了不同的方法解析同一个包,这才导致出现解析错误,从而造成CRLF攻击。
-Content-Length
使用Content-Length直接直译就好了。无非就是内容的长度。
1 | POST /search HTTP/1.1 |
-Transfer-Encoding
使用Transfer-Encoding头指定请求体正文使用分块编码。这意味着消息正文包含一个或多个数据块。每块的组成为:字节为单位的块的大小(以十六进制表示),换行符,块内容, 该消息以大小为0的块终止。(并不是以0终止哦。)
1 | POST /search HTTP/1.1 |
BurpSuite会自动解压缩分块的编码,以便在请求中更易于查看和编辑。在浏览器中通常不会在请求中使用哪个分块编码,通常只能在服务器响应中看到。
由于HTTP规范提供了两种解析规范,因此就像上文所说的,当一个消息可能会同时使用这两种方法,从而使他们彼此冲突。RFC2616规范试图通过指出如果同时存在Content-Length标头和Transfer-Encoding标头来防止此问题,则应该忽略Content-Length标头。
1 | 如果接收的消息同时包含传输编码头字段(Transfer-Encoding)和内容长度头(Content-Length)字段,则必须忽略后者。 |
当仅使用一台服务器时,这足以避免歧义,但是当将两个或多个服务器链接在一起时,这并不能避免歧义。在这种情况下,可能由于两个原因而出现问题:
-某些服务器在请求中不支持Transfer-Encoding标头。
-如果以某种方式混淆了标头,则某些确实支持Transfer-Encoding标头的服务器将不被处理。
如果前端服务器和后端服务器在(可能是混淆的)Transfer-Encoding标头的行为不同,则它们可能在连续请求之间的边界上存在分歧,从而导致请求走私漏洞。
扩展:为什么会出现多次请求
这与最为广泛的HTTP 1.1的协议特性——Keep-Alive&Pipeline有关。
在HTTP1.0之前的协议设计中,客户端每进行一次HTTP请求,需要同服务器建立一个TCP链接。
而现代的Web页面是由多种资源组成的,要获取一个网页的内容,不仅要请求HTML文档,还有JS、CSS、图片等各种资源,如果按照之前的协议设计,就会导致HTTP服务器的负载开销增大。于是在HTTP1.1中,增加了Keep-Alive和Pipeline这两个特性。
-Keep-Alive:在HTTP请求中增加一个特殊的请求头Connection: Keep-Alive,告诉服务器,接收完这次HTTP请求后,不要关闭TCP链接,后面对相同目标服务器的HTTP请求,重用这一个TCP链接。这样只需要进行一次TCP握手的过程,可以减少服务器的开销,节约资源,还能加快访问速度。这个特性在HTTP1.1中默认开启的。
-Pipeline(HTTP管线化):http管线化是一项实现了多个http请求但不需要等待响应就能够写进同一个socket的技术,仅有http1.1规范支持http管线化。在这里,客户端可以像流水线一样发送自己的HTTP请求,而不需要等待服务器的响应,服务器那边接收到请求后,需要遵循先入先出机制,将请求和响应严格对应起来,再将响应发送给客户端。
现在,浏览器默认不启用Pipeline的,但是一般的服务器都提供了对Pipleline的支持。
下面这是典型的CDN加速图和拓扑结构图CDN加速图

拓扑结构图
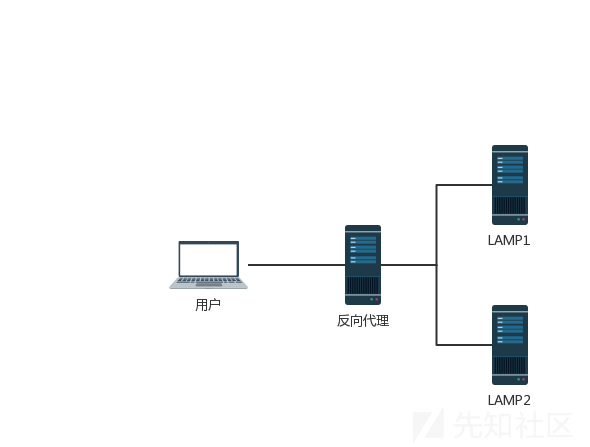
0x03 CRLF利用
HTTP请求走私攻击将Content-Length标头和Transfer-Encoding标头选两个放在单个HTTP请求中,并对其进行处理,一遍侵短服务器和后端服务器以不同的方式处理请求。完成此操作的确切方式取决于链各个服务器的行为。
-CL!=0:所有不携带请求体的HTTP请求都有可能受此影响。这里用GET请求举例。前端代理服务器允许GET请求携带请求体;后端服务器不允许GET请求携带请求体,它会直接忽略掉GET请求中的Content-Length头,不进行处理。这就有可能导致请求走私。
-CL-CL:在RFC7230的第3.3.3节中的第四条中,规定当服务器收到的请求中包含两个Content-Length,而且两者的值不同时,需要返回400错误。但是
-CL-TE:就是当收到存在两个请求头的请求包时,前端代理服务器只处理Content-Length请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding请求头。
-TE-CL:所谓TE-CL,就是当收到存在两个请求头的请求包时,前端代理服务器处理Transfer-Encoding这一请求头,而后端服务器处理Content-Length请求头。
-TE-TE:也很容易理解,当收到存在两个请求头的请求包时,前后端服务器都处理Transfer-Encoding请求头,这确实是实现了RFC的标准。不过前后端服务器毕竟不是同一种,这就有了一种方法,我们可以对发送的请求包中的Transfer-Encoding进行某种混淆操作,从而使其中一个服务器不处理Transfer-Encoding请求头。从某种意义上还是CL-TE或者TE-CL。
CL!=0
就是CL不为0的GET请求。
1 | GET / HTTP/1.1\r\n |
前端服务器收到该请求,读取Content-Length请求头,认为这是一个完整的请求,但是后端服务器收到后,并不对Content-Length进行处理。由于Pipeline的存在,它认为收到了两个请求,就导致了请求走私。
CL-CL
1 | 在RFC7230的第3.3.3节中的第四条中,规定当服务器收到的请求中包含两个Content-Length,而且两者的值不同时,需要返回400错误。 |
但是有些服务器不会严格的实现该规范,假设中间的代理服务器和后端的源码服务器在收到类似的请求时,都不会返回 400 错误。但是中间的代理服务器按照第一个Content-Length的值对请求进行处理,而后端源站服务器按照第二个Content-Length的值进行处理。
请求示例:
1 | POST / HTTP/1.1\r\n |
中间的代理服务器使用第一个Content-Length,获得的长度为8。将上述整个数据包原封不动的转发给后端的源站服务器,而后端服务器获取到的数据包长度为7。当读取完7个字符后,后端默认最后的a是下一个数据包的,从而造成CRLF。
实验
Buuctf Easy_calc
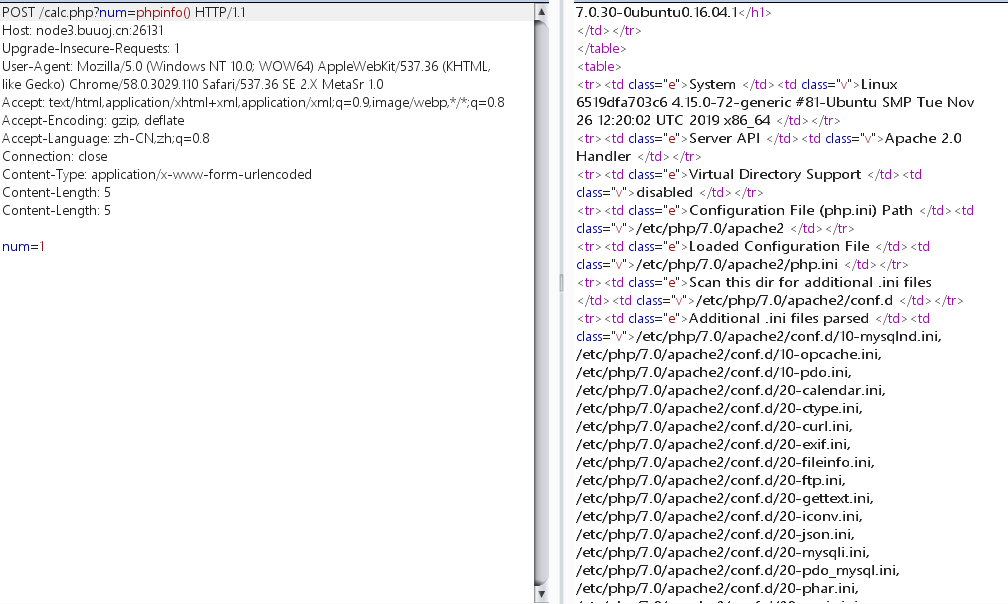
本来我是不懂的,但是峰佬告诉我说,这是因为即使会爆400,但是前端服务器依旧把数据包发送给了后端服务器。从而导致命令执行。我只能说,我相信峰佬好吧。
CL-TE
1 | POST / HTTP/1.1 |
前端服务器处理Content-Length标头,并确定请求主题的长度为13个字节,为什么是13呢?因为每一个我们可以看到的换行其实是\r\n。这算两个字符,所以再数一遍就是13个字符啦。
后端服务器处理Transfer-Encoding标头,将消息视为分块编码。而0数据块就是结束符。 接下来的字节SMUGGLED未经处理,后端服务器会将其视为序列中下一个请求的开始。
实验
https://portswigger.net/web-security/request-smuggling/lab-basic-cl-te
1 | 本实验涉及前端服务器和后端服务器,并且前端服务器不支持分块编码。前端服务器拒绝使用GET或POST方法之外的请求。 |

记住要多发几次,原理就不说了吧,自己思考一下。其实上面也说了。
1 | -请求为POST |
TE-CL
1 | POST / HTTP/1.1 |
1 | 要使用Burp Repeater发送此请求,您首先需要转到Repeater菜单,并确保未选中 “Update Content-Length”选项 |
这里前端服务器只处理Transfer-Encoding这一请求头,所以读到0数据块结束,然后把包发到后端服务器。而我们的后端服务器处理Content-Length请求头,导致只读取了3个字节。剩下的SMUGGLED会被当做下一个请求的一部分,从而导致CRLF。
实验
https://acd71f7d1eb80bb18188c6a500c400ed.web-security-academy.net/
1 | 本实验涉及前端服务器和后端服务器,后端服务器不支持分块编码。前端服务器拒绝使用GET或POST方法之外的请求。 |
在实验前记得关闭BurpSuite自带的补齐功能,实验完记得补上。


TE-TE
前端服务器和后端服务器都支持Transfer-Encoding请求头,但是可以对其进行混淆来诱导一台服务器不进行处理。
1 | Transfer-Encoding: xchunked |
要发现TE-TE漏洞,必须找到Transfer-Encoding标头的某些变体,以便只有前端服务器或后端服务器之一对其进行处理,而另一服务器将其忽略。 这取决于是否诱使前端服务器或后端服务器不处理混淆的Transfer-Encoding标头,其余的攻击将采用与CL-TE或TE-CL漏洞相同的形式已经描述过了。 –来自fenghlz.xyz
我来解释一下把,TE-TE有两种方式,一种是前端服务器不解析TE,一种是后端服务器不解析TE。而这两种情况其实都可以结合上面的两种方法来进行CRLF攻击。
实验
https://portswigger.net/web-security/request-smuggling/lab-basic-te-cl
1 | 本实验涉及前端服务器和后端服务器,后端服务器不支持分块编码。前端服务器拒绝使用GET或POST方法之外的请求。 |
记得继续关闭自动补全呀!

原理:后端服务器被混淆,不处理Transfer-Encoding请求头,使用Content-Length请求头。
0x04 漏洞修复
1 | 1、将前端服务器配置为只使用HTTP/2与后端系统通信 |
0x05 参考资料
先知社区 从一道题到协议层攻击之HTTP请求走私
https://xz.aliyun.com/t/6654#toc-6
FengHLZ博客 HTTP请求走私攻击
Paper 协议层的攻击——HTTP请求走私